From Categories to Fields: A Multi-Outcome Map of Mental Health
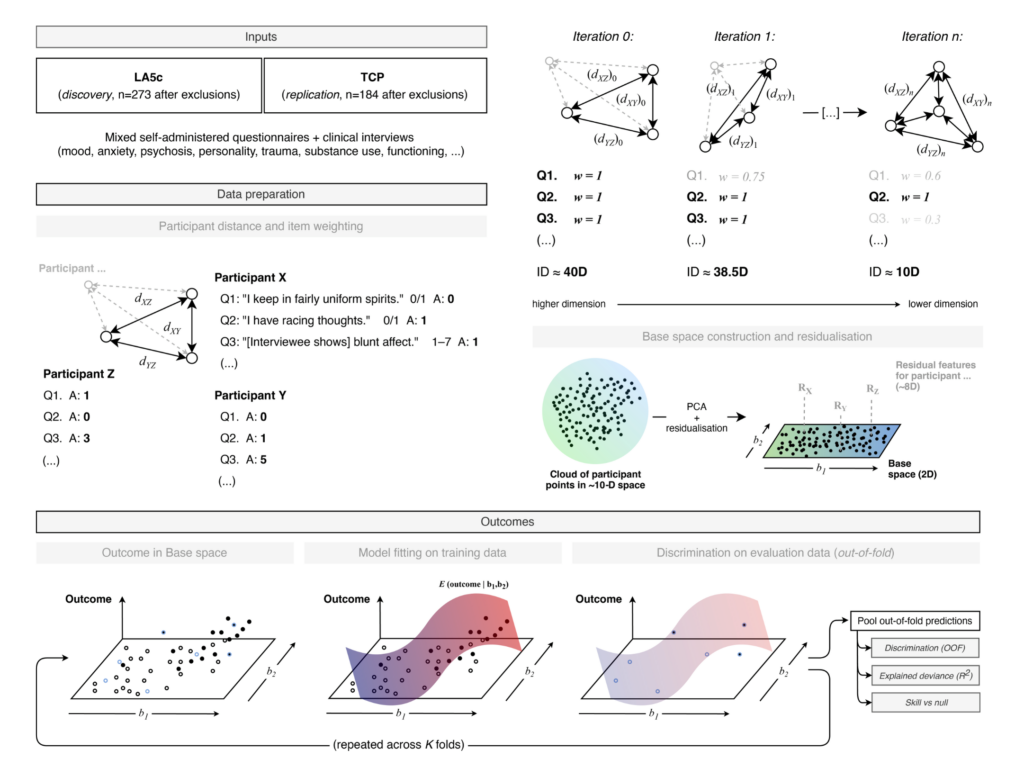
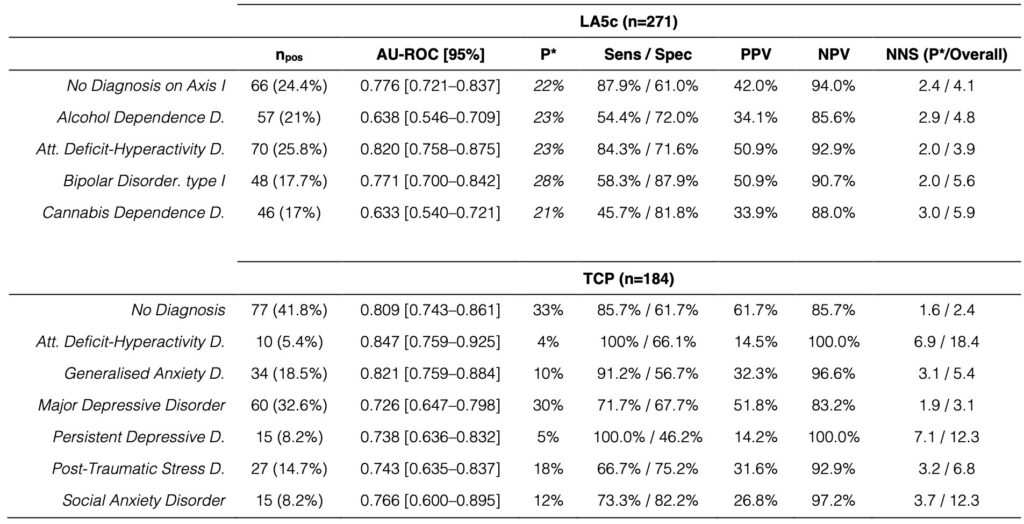
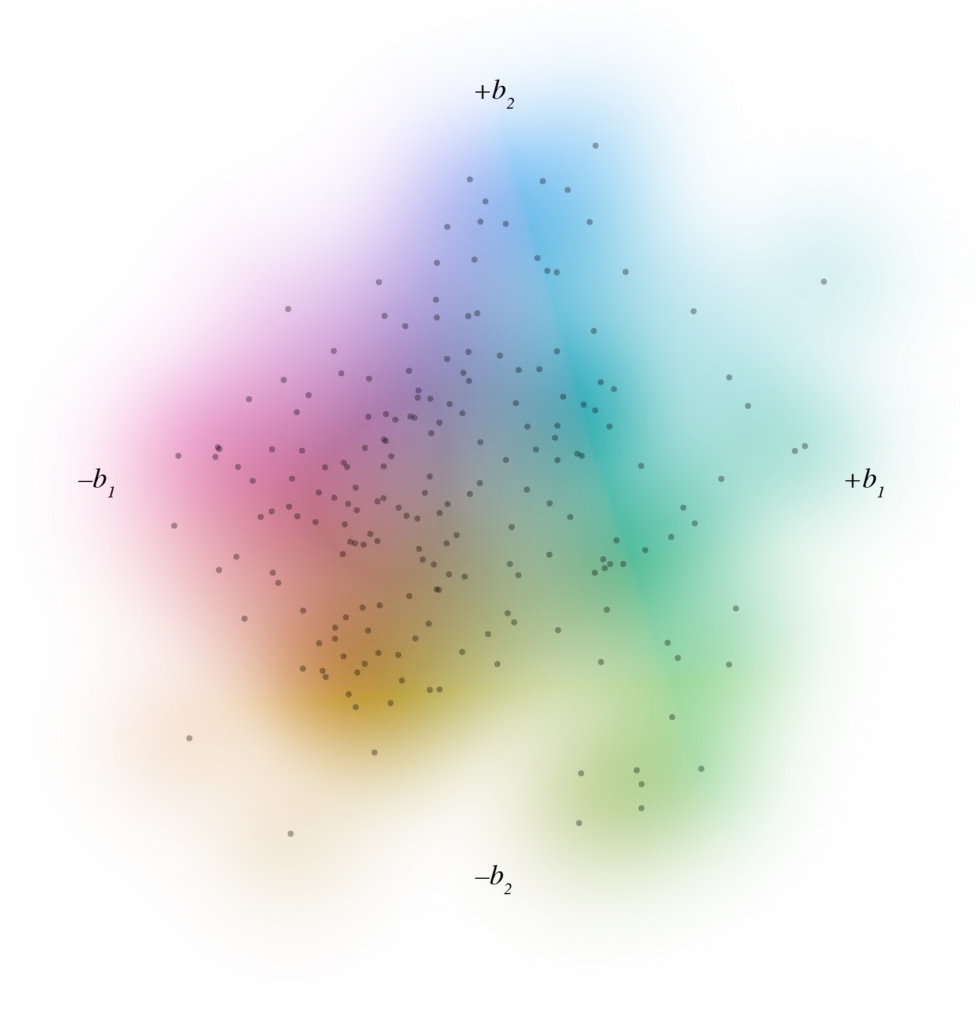
This project builds a two-dimensional map of individual psychometric profiles and uses it as a shared coordinate system for diagnoses, symptoms, functioning and treatment burden. Item-level questionnaire and interview data from two independent transdiagnostic cohorts are treated each as mixed-scale feature spaces. Similarity between participants is quantified within this space, and a robust principal-components step turns that into a low-dimensional base in which each point represents a participant. On top of that base, DSM diagnoses and other variables are modelled as smooth probability or value fields using cross-validated generalised additive models, so the output is a set of calibrated risk surfaces rather than a series of case–control contrasts.
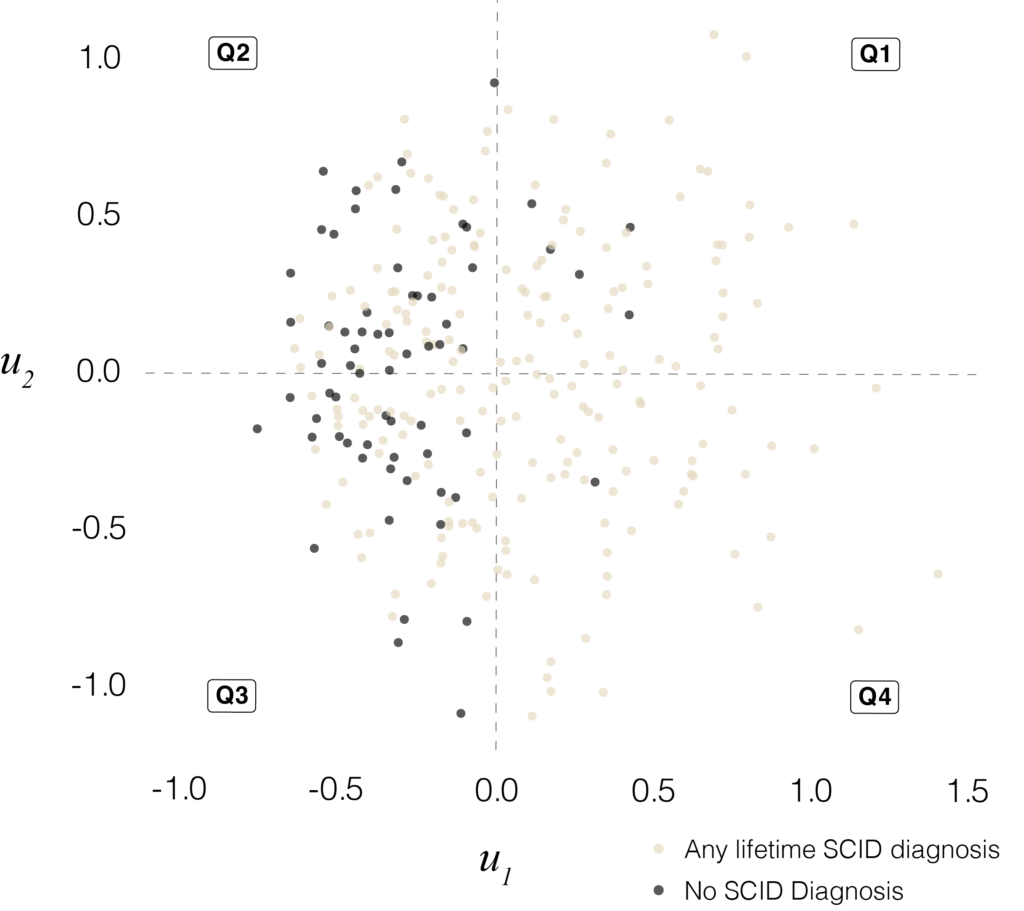
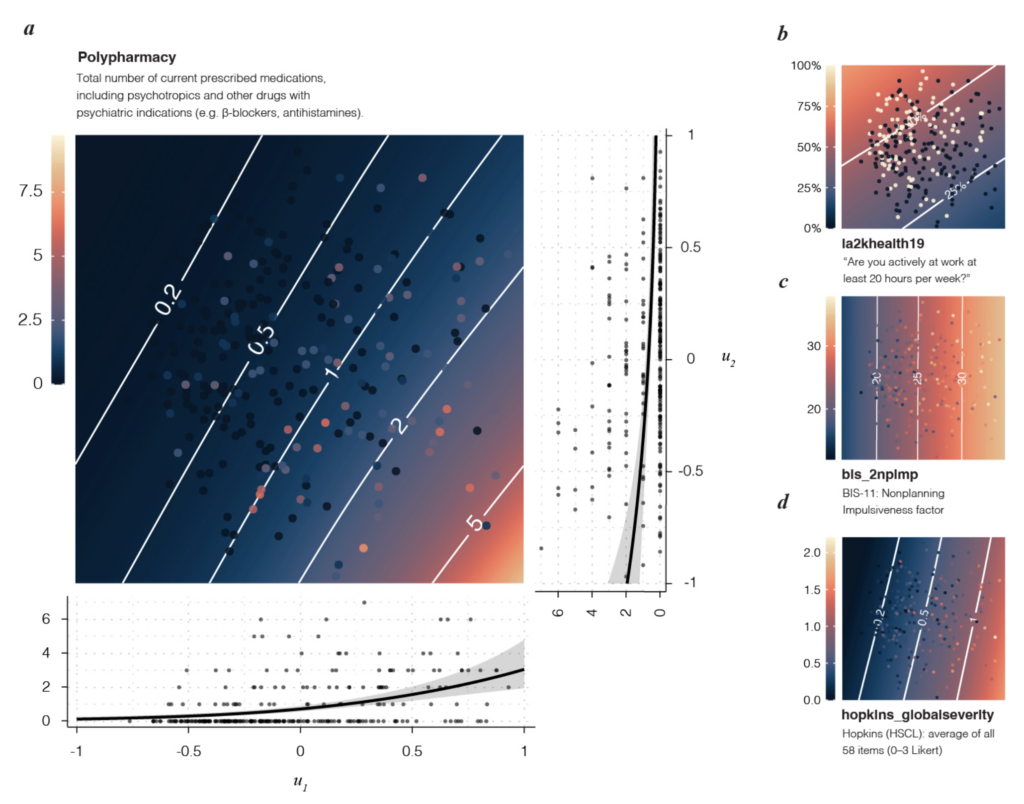
In this geometry, mood, anxiety, established diagnoses, functioning, occupy overlapping, graded regions of the space rather than cleanly separated clusters. Symptom scales, response-style indices, work status, polypharmacy and simple structural MRI measures all follow coherent gradients through the same map. Taken together, these fields form an atlas of mental-health burden that can be reused across instruments and cohorts and that lends itself to service stratification, trial enrichment and longitudinal trajectory work.
The pipeline standardises mixed item types, drops degenerate or near-empty variables, collapses near-duplicate profiles, checks intrinsic dimensionality and only then fixes the embedding. All outcome fields are estimated strictly out of sample, and the system produces diagnostics for map stability, leverage points and residual structure.
The organising principle is consistent across the analyses, with the geometry learned without labels and outcomes modelled afterwards under conservative validation.
Manuscript available on Zenodo ↳
Code on Github ↳
Other projects
I have also used adapted versions of this framework on large public datasets, including NHANES ↳, VitalDB ↳, and other datasets of comparable size in clinical and non-clinical areas.
These analyses have been used to stress-test the stability of the representation under different variable sets and data quality, and to verify that established gradients in age, socioeconomic status, and cardiovascular-metabolic risk are recovered in a way that is intuitively intelligible.
Current focus
At present, my work concentrates on atlas-style representations of high-dimensional clinical, psychometric, and survey data. I am pushing these methods into larger and more heterogeneous datasets, including linked routine data and longitudinal cohorts, to verify where the geometry remains stable, and where it needs to be adapted. The focus is on keeping the representations reusable across studies so that risk fields and trajectories can be compared directly, rather than reconstructed “from scratch” for each analysis.